Structured Data
Introduction
When reading web pages, we consume unstructured content. We read paragraphs, examine media, and consider what we digest. As part of that process, we apply intuition and context (such as subject-matter familiarity) to identify key themes, data points, entities, and relationships. As humans, we’re very good at this.
But this kind of intuition and context is difficult for software to replicate. It’s difficult for systems to reliably parse, identify, and extract key themes with a high degree of reliability.
These limitations can constrain the kinds of things which we can effectively build and create, and limits how “smart” web technology can be.
By introducing structure to information, we can make it much easier for software to understand content. We do this by adding labels and metadata which identify key concepts and entities—as well as their properties and relationships.
When machines can reliably extract structured data, at scale, we enable new and smarter types of software, systems, services and businesses.
The goal of the Web Almanac’s Structured Data chapter is to explore how structured data is currently being used across the web. We hope that this will provide insight into the landscape, the challenges, and the opportunities at hand.
This is the first time that this chapter has been included in the Web Almanac, and so we unfortunately lack historical data for the purposes of comparison. Future chapters will also explore year-on-year trends.
Key concepts
Structured data is a complex landscape, and one which is by nature abstract and ’meta’. To understand the significance and potential impact of structured data, it’s worth exploring the following key concepts.
The semantic web
When we add structured data to public web pages—and we define the entities that those pages contain (or are about, or reference)—we create a form of linked data.
We make statements about the things in (and related to) our content in the form of triples. Statements like, “This article was authored by this person”, or “That video is about a cat”.
Describing our content in this way enables machines to treat web pages and websites as databases. At scale, it creates a semantic web; a giant global database of information.
The Semantic Web is the name of a long-term project started by W3C with the stated purpose of realizing the idea of having data on the Web defined and linked in a way that it can be used by machines not just for display purposes, but for automation, integration, and reuse of data across various applications
That creates a wealth of possibilities for business, technology, and society.
Search engines, and beyond
To date, some of the broadest consumers of structured data are search engines and social media platforms.
In most major search engines, website owners may become eligible for various forms of rich results (which may influence visibility and traffic) by implementing various types of structured data on their websites.
In fact, search engines have played such a significant role in the general adoption of (and education around) structured data across the web, that this chapter was born out of Web Almanac SEO chapters from previous years. In recent years, the influence of search engines has also popularized schema.org the vocabulary of choice for structured data.
In addition to this, social media platforms rely on structured data to influence how they read and display content when it’s shared (or linked to) on their platforms. Rich previews, tailored titles and descriptions, and interactivity in these platforms are often powered by structured data.
But there’s more to see and understand here than search engine optimization and social media benefits. The scale, variety, impact and potential of structured data goes far beyond rich results, far beyond search engines, and far beyond schema.org.
For example, structured data facilitates:
- Easier topic modelling and clustering across multiple pages, websites and concepts; enabling new types of research, comparison and services.
- Enriching analytics data, to allow for deeper and horizontalized analysis of content and performance.
- Creating a unified (or at least, connected) language and syntax for querying business systems and website content.
- Semantic search; using the same rich metadata used for search engine optimization, to create and manage internal search systems.
Whilst the findings of our research are inevitably shaped by the influence of search engines, we hope to also explore other types, formats, and use-cases of structured data.
Types of structured data and coverage
Structured data comes in many formats, standards, and syntaxes. We’ve collected data about the most common of these across our data set.
Specifically, we’ve identified and extracted structured data relating to:
- Schema.org
- Dublin core
- Meta tags used by social networks:
- Microformats (and microformats2)
- RDFa, Microdata and JSON-LD
Collectively, these provide a broad overview of different use-cases and scenarios; and include both legacy standards and modern approaches (e.g., microformats vs JSON-LD).
Before we explore specific usage across the various structured data types, we should briefly explore some caveats.
Data caveats
1. The influence of Content Management Systems
Many of the pages we’ve evaluated are from websites which use a Content Management System (CMS), such as WordPress or Drupal. These systems—or the themes/plugins/modules which enhance their functionality—are often responsible for generating the HTML markup which contains the structured data which we’re analyzing.
That means that our findings are unavoidably skewed to aligning with the behaviors and output of the most prevalent CMS’. For example, many websites using Drupal automatically output structured data in the form of RDFa, and WordPress (which powers a significant percentage of websites) often includes microformats markup in template code. This contributes significantly to the shape of our findings.
2. The limitations of home page-only data
Unfortunately, the nature and scale of our data-collection methods limit our analysis to home pages only (i.e., the root URL of each hostname we evaluate).
This significantly limits the amount of data we can collect and analyze, and undoubtedly skews the kinds of data we’ve collected.
As most home pages act as portals to more specific pages, we can reasonably expect that our analysis underestimates the prevalence of the kinds of content present on that deeper pages. That likely includes information relating to articles, people, products and similar.
Conversely, we likely over-index on information typically found on home pages, and site-wide information which is present on all pages—like information about web pages, websites and organizations.
3. Data overlaps
The nature of some structured data formats makes it hard to perform this kind of analysis cleanly at scale. In many cases, structured data is implemented in multiple (often overlapping) formats, and the lines between syntaxes and vocabularies get blurred.
For example, Facebook and Open Graph metadata are technically a subset of RDFa. That means that our research identifies a page containing a Facebook meta tag in our Facebook category, and our RDFa section. We’ve done our best to clean, normalize, and make sense of these types of overlaps and nuances.
4. Mobile metrics
Throughout our data set, the adoption and presence of structured data varies only very slightly between our desktop and mobile data sets. As such, for the sake of brevity, our narrative focuses predominantly on the mobile data set.
Usage by type
We can see that there’s a broad range of different types of structured data across many of the pages in our set.
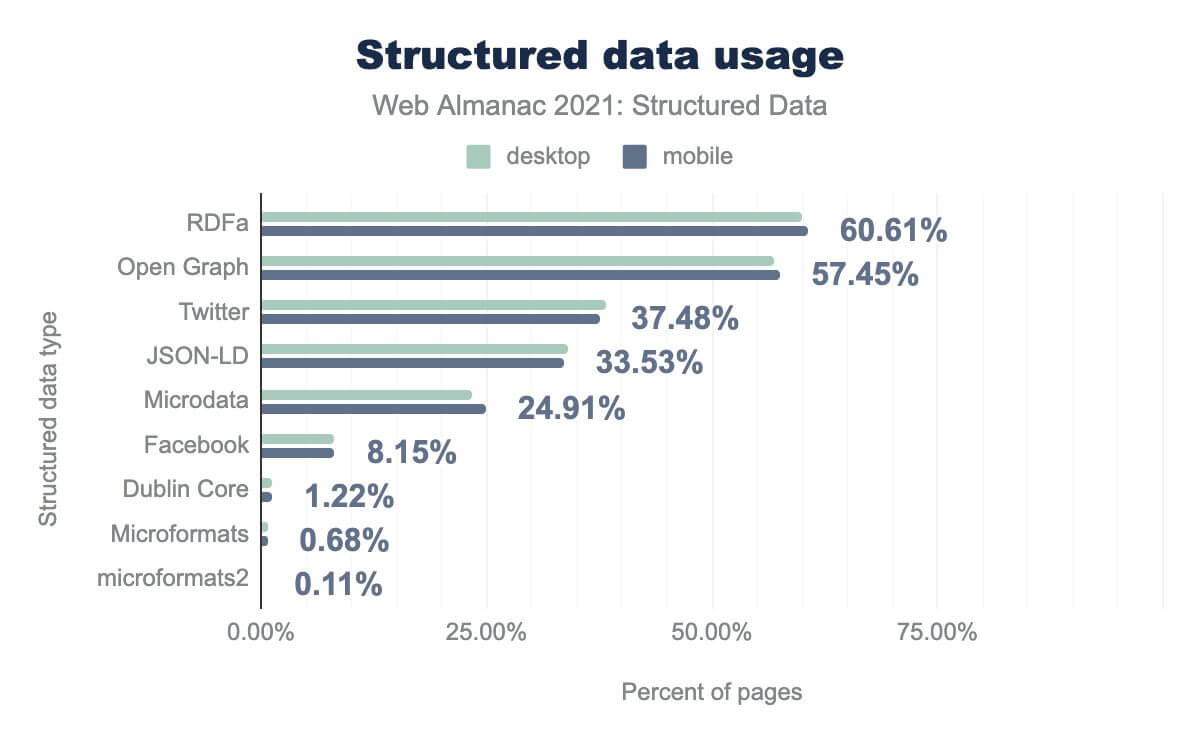
We can also see that RDFa and Open Graph tags in particular are extremely prevalent, appearing on 60.61% and 57.45% of pages respectively.
At the other end of the scale, legacy formats, like Microformats and microformats2, appear on fewer than 1% of pages.
Coverage by syntax type
In addition to identifying when a certain type of structured data is present, we collect information on the types of data it describes. We can break each of these down and explore how each format and syntax is being used.
RDFa
Resource Description Framework in Attributes (RDFa) is a technology for linked data markup, which was introduced by W3C in 2015. It allows users to augment and translate visual information on a web page by adding additional attributes to markup.
For example, a website owner might add a rel="license" attribute to a hyperlink in order to explicitly describe it as a link to a licensing information page.
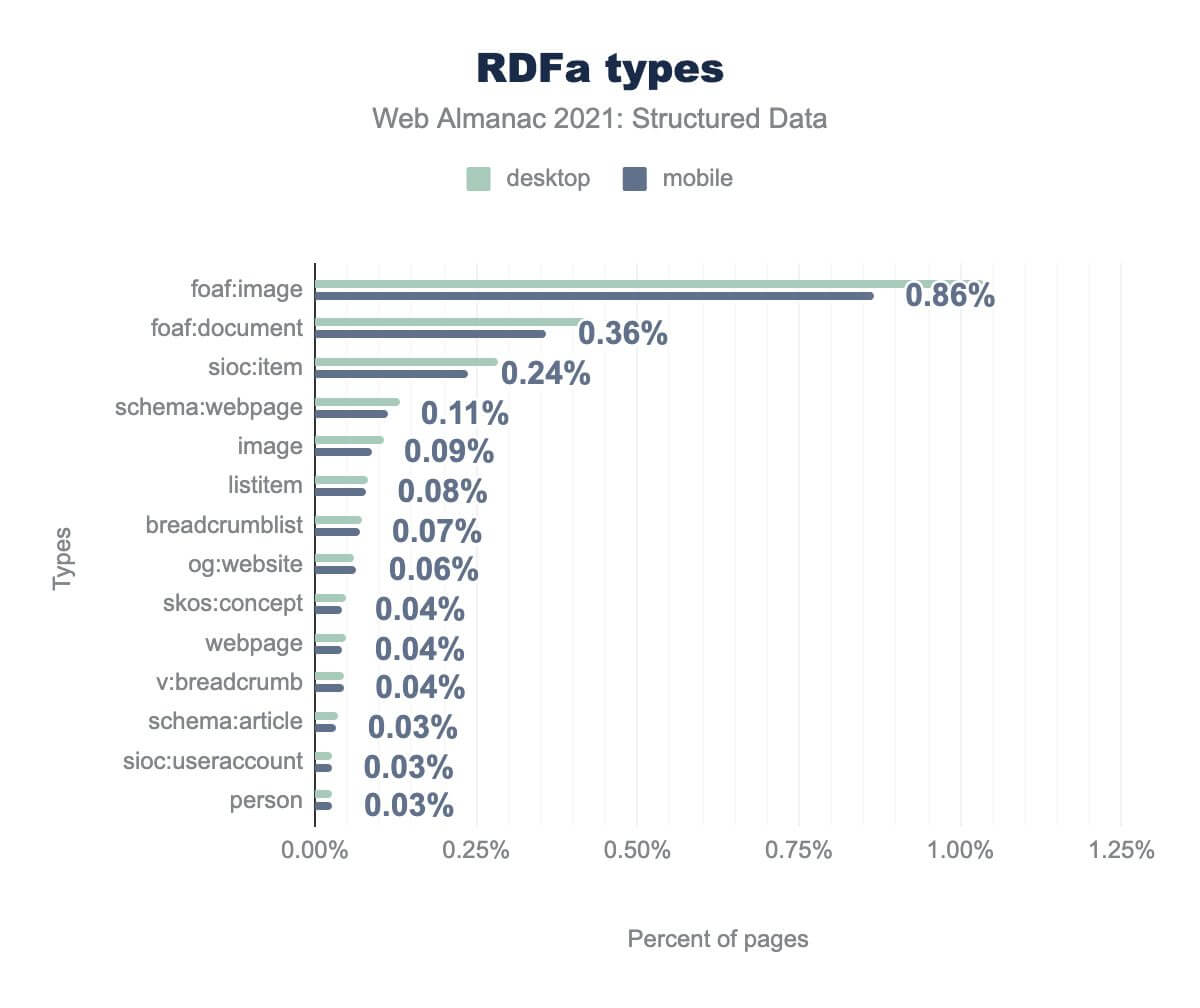
foaf:image is on 0.86%, foaf:document is on 0.36%, sioc:item is on 0.24%, schema:webpage is on 0.11%, image is on 0.9%, listitem is on 0.08%, breadcrumblist is on 0.07%, og:website is on 0.06%, skos:concept is on 0.04%, webpage is on 0.04%, v:breadcrumb is on 0.04%, schema:article is on 0.03%, sioc:useraccount is on 0.03%, and person is on 0.03%. Desktop usage is similar.When we evaluate the types of RDFa, we can see that the foaf:image syntax is present on far more pages than any other type—on upwards of 0.86% of all pages in our data set. Whilst that may seem like a small proportion, it represents over ~65,000 pages, and over 60% of the total RDFa markup that we discovered.
Beyond this outlier, the use of RDFa diminishes and fragments considerably, though there are still some interesting discoveries to explore.
On FOAF
FOAF (or “Friend of a Friend”) is a linked data dictionary of people-related terms, created in the early-2000s. It can be used to describing people, groups and documents.
FOAF uses W3C’s RDF syntax and in its original introduction was explained as follows:
Consider a Web of inter-related home pages, each describing things of interest to a group of friends. Each new home page that appears on the Web tells the world something new, providing factoids and gossip that make the Web a mine of disconnected snippets of information. FOAF provides a way to make sense of all this.
Anecdotally, we can attribute a prominence of foaf markup in our results to sites running on older versions of the Drupal CMS, which historically added typeof="foaf:image" and foaf:document markup to its HTML by default.
On other notable RDFa findings
As well as FOAF properties, various other standards and syntaxes show up in our list.
Notably, we can see several sioc properties, such as sioc:item (0.24% of pages) and sioc:useraccount (0.03% of pages). SIOC is a standard designed to describe structured data relating to online communities, such as message boards, forums, wikis and blogs.
We can also see a SKOS (or “Simple Knowledge Organization System”) property—skos:concept—on 0.04% of pages. SKOS is another standard, which aims to provide a way of describing taxonomies and classifications (e.g., tags, data sets, and so on).
Dublin Core
Dublin Core is a vocabulary interoperable with linked data standards that was originally conceived in Dublin, Ohio in 1995 at an OCLC (Online Computer Library Center) and NCSA (National Center for Supercomputing Applications) workshop.
It was designed to describe a broad range of resources (both digital and physical) and can be used in various business scenarios. Starting in 2000 it became extremely popular among RDF-based vocabularies and received the adoption of the W3C.
Since 2008 it is managed by the Dublin Core Metadata Initiative (DCMI) and remains highly interoperable with other linked data vocabularies. It is typically implemented as a collection of meta tags in an HTML document.

dc.title is on 0.70%, dc.language is on 0.49%, dc.description is on 0.44%, dc.publisher is on 0.22%, dc.creator is on 0.21%, dc.subject is on 0.20%, dc.source is on 0.19%, dc.identifier is on 0.17%, dc.relation is on 0.16%, dcterms.title is on 0.15%, dc.type is on 0.14%, dcterms.rightsholder is on 0.12%, and dcterms.identifier is on 0.11%. Desktop usage is similar.That the most popular attribute type is dc:title (on 0.70% of pages) comes as no surprise; but it is interesting to see that dc:language is next (above common descriptors like description, subject and publisher) with a penetration of 0.49%. This makes sense, when you consider that Dublin Core is often used in multilingual metadata management systems.
It’s also interesting to see the relatively prominent appearance of dc:relation (on 0.16% of pages)—an attribute that is capable of expressing relationships between different concepts.
While it might seem to many that Schema.org is predominant in the context of SEO, the role of DC remains pivotal because of its broad interpretation of concepts and its deep roots in the linked open data movement.
Social metadata
Social networks and platforms are some of the biggest publishers and consumers of structured data. This section explores the roles, breadth of adoption, and scale of some of their specific structured data formats.
Open Graph
The Open Graph protocol is an open-source standard, originally created by Facebook. It is a type of structured data specific to the context of sharing content, based loosely on Dublin Core, Microformats and similar standards.
It describes a series of meta tags and properties, which may be used to define how content should be (re)presented when shared between platforms. For example, when liking or embedding a post, or sharing a link.
These tags are typically implemented in the <head> of an HTML document, and define elements such as the page’s title, description, URL, and featured image.
The Open Graph protocol has since been broadly adopted by many platforms and services, including Twitter, Skype, LinkedIn, Pinterest, Outlook and more. When platforms don’t have their own standards for how shared/embedded content should be presented (and sometimes, even when they do), Open Graph tags are often used to define the default behavior.

og:title is on 54.87%, og:url is on 52.03%, og:type is on 48.18%, og:description is on 48.55%, og:site_name is on 43.37%, og:image is on 36.98%, og:locale is on 26.39%, og:image:width is on 12.95%, og:image:height is on 12.91%, og:image:secure_url is on 5.61%, og:image:alt is on 1.75%, og:image:type is on 1.61%, og:updated_time is on 1.54%, and og:locale:alternate is on 0.87%. Desktop usage is similar.The most common type of Open Graph tag is the og:title, which can be found on an incredible 54.87% of pages. That’s followed closely by a set of related attributes, which describe what type of thing is being represented (e.g., og:type, on 48.18% of pages) and how it should be represented (e.g., og:description, on 48.55% of pages).
This narrow distribution is to be expected, as these tags are often used together as part of a “boilerplate” set of tags used in the <head> across all pages on a site.
Slightly less common is og:locale (26.39% of pages), which is used to define the language of the page’s content.
Less common still is more specific metadata about the og:image tag, in the form of og:image:width (12.95% of pages), og:image:height (12.91% of pages), og:image:secure_url (5.61% of pages) and og:image:alt (1.75% of pages). It’s worth noting that with HTTPS adoption now increasingly the norm, og:image:secure_url (which was intended to identify a https version of the og:image) is now largely redundant.
Beyond these examples, usage drops off rapidly, into a long tail of (often malformed, deprecated or erroneous) tags.
Though Twitter uses Open Graph tags as fallbacks and defaults, the platform supports its own flavor of structured data. A set of specific meta tags (all prefixed with twitter:) can be used to define how pages should be presented when URLs are shared on Twitter.
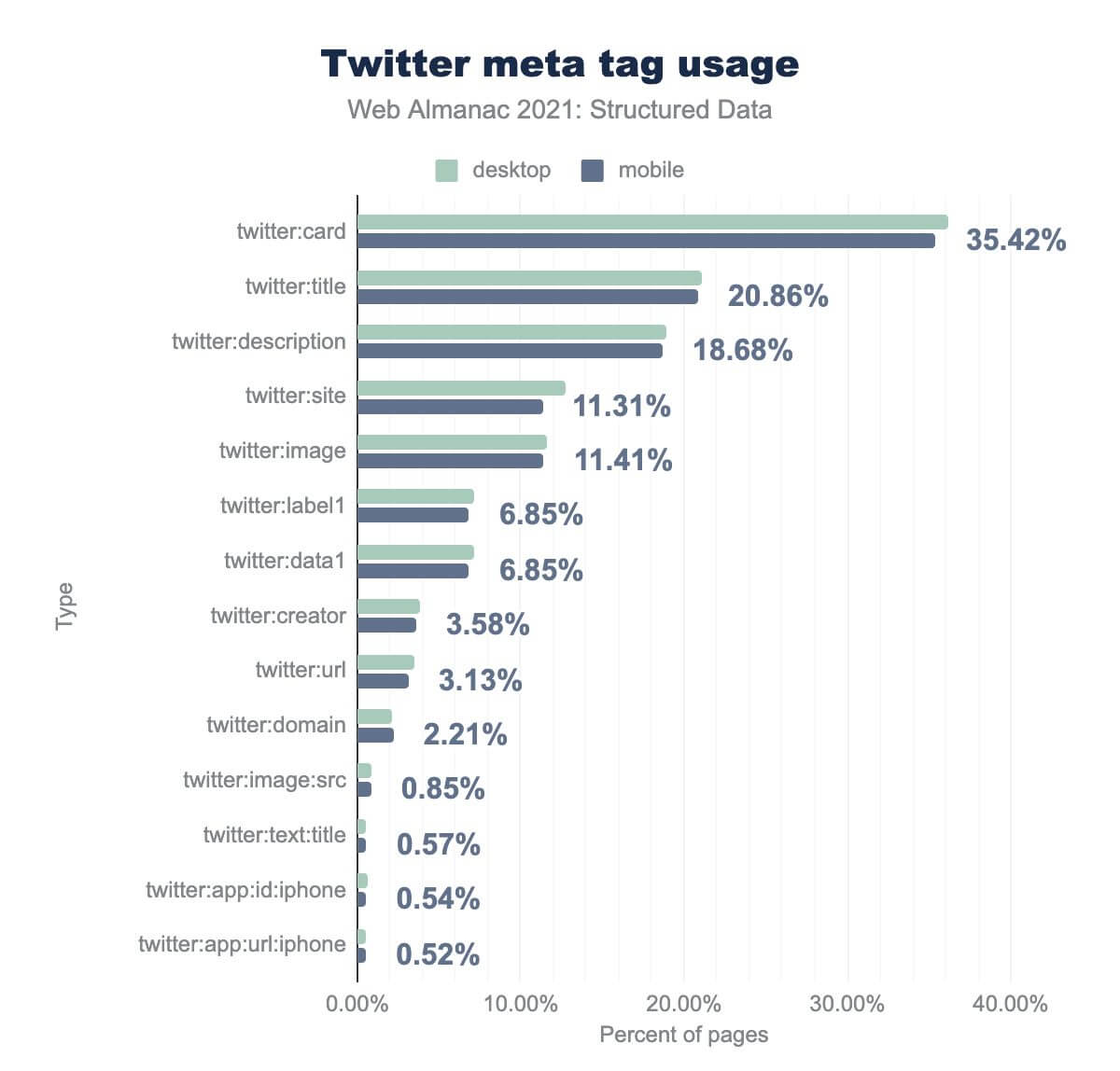
twitter:card is on 35.42%, twitter:title is on 20.86%, twitter:description is on 18.68%, twitter:site is on 11.31%, twitter:image is on 11.41%, twitter:label1 is on 6.85%, twitter:data1 is on 6.85%, twitter:creator is on 3.58%, twitter:url is on 3.13%, twitter:domain is on 2.21%, twitter:image:src is on 0.58%, twitter:text:title is on 0.57%, twitter:app:id:phone is on 0.54%, and twitter:app:url:iphone is on 0.52%. Desktop usage is similar.The most common Twitter meta tag is twitter:card, which was found on 35.42% of all pages. This tag can be used to define how pages should be presented when shared on the platform (e.g., as a summary, or as a player when paired with additional data about a media object).
Beyond this outlier, adoption drops off steeply. The next most common tags are twitter:title and twitter:description (both also used to define how shared URLs are presented), which appear on 20.86% and 18.68% of all pages, respectively.
It’s understandable why these particular tags—as well as the twitter:image tag (11.41% of pages) and twitter:url tag (3.13% of pages)—aren’t more prevalent, as Twitter falls back to the equivalent Open Graph tags (og:title, og:description and og:image) when they’re not defined.
Also of interest are:
- The
twitter:sitetag (11.31% of pages) which defines the Twitter account associated with the website in question. - The
twitter:creatortag (3.58% of pages), which defines the Twitter account of the author of the web page’s content. - The
twitter:label1andtwitter:data1tags (both on 6.85% of pages), which can be used to define custom data and attributes about the web page. Additional label/data pairs (e.g.,twitter:label2andtwitter:data2) are also present on a significant number (0.5%) of pages.
Beyond these examples, usage drops off rapidly, into a long tail of (often malformed, deprecated or erroneous) tags.
In addition to Open Graph tags, Facebook supports additional metadata (meta tags, prefixed with fb:) for relating web pages to specific brands, properties and people on their platform.
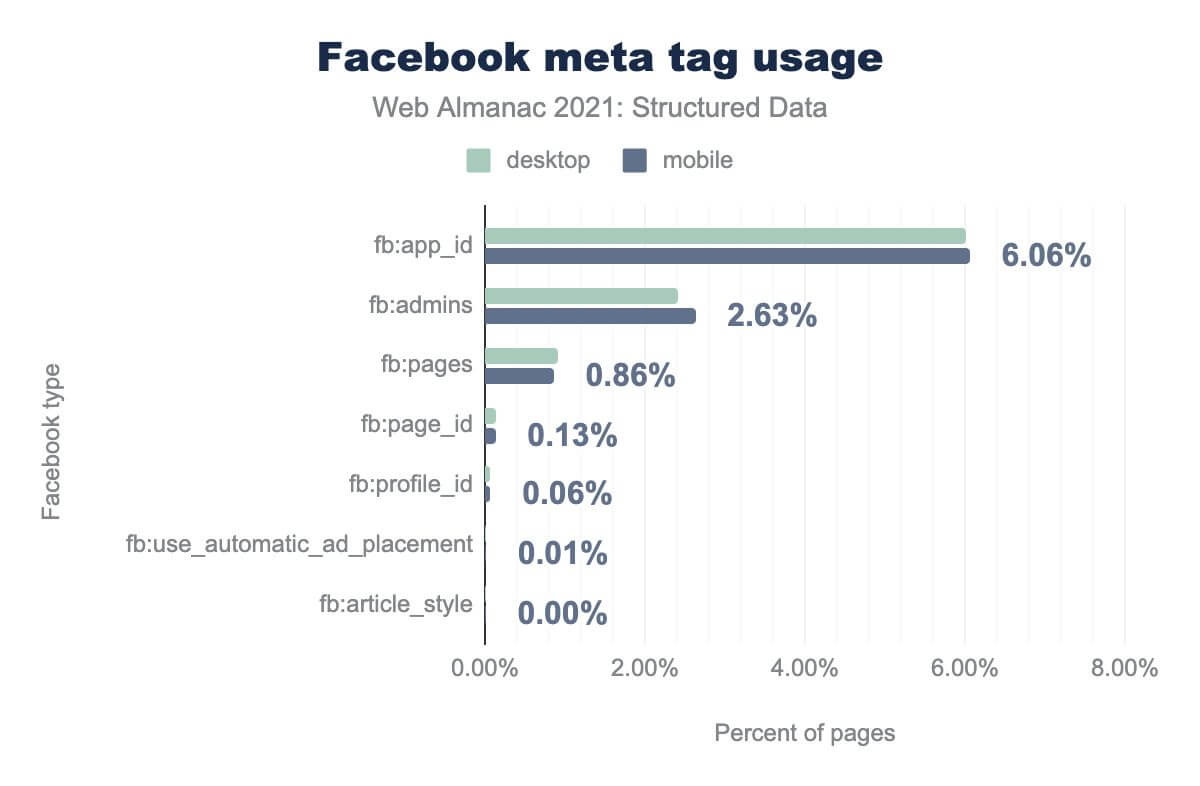
fb:app_id is on 6.06%, fb:admins is on 2.63%, fb:pages is on 0.86%, fb:page_id is on 0.13%, fb:profile_id is on 0.06%, fb:use_automatic_ad_placement is on 0.01%, and fb:article_style is on less than 0.01%. Desktop usage is similar.Of all of the Facebook tags that we detected, there are only three tags with significant adoption.
Those are fb:app_id, fb:admins, and fb:pages; which we found on 6.06%, 2.63% and 0.86% of pages respectively.
These tags are used to explicitly relate a web page to a Facebook Page/Brand, or to grant permissions to a user (or users) who administrates those profiles.
Anecdotally, it’s unclear how well these are supported by Facebook. The platform has gone through radical changes over the past few years, and their technical documentation hasn’t been well-maintained. However, many content management systems, templates and best practice guides—as well as some of Facebook’s debugging tools—still include and make reference to them.
Microformats and microformats2
Microformats (commonly abbreviated as μF) are an open data standard for metadata to embed semantics and structured data in HTML.
They are composed of a set of defined classes that describe the meanings behind normal HTML elements, such as headings and paragraphs.
The guiding principle behind this format for structured data is to convey semantics by reusing widely adopted standards (semantic (X)HTML). The official documentation describes Microformats as “designed for humans first and machines second”, and are “a set of simple, open data formats built upon existing and widely adopted standards”.
Microformats are available in two versions: Microformats v1 and Microformats v2 (microformats2). The latter, introduced in March 2014, replaces and supersedes v1 and takes advantage of some important lessons learned from both microdata and RDFa syntaxes.
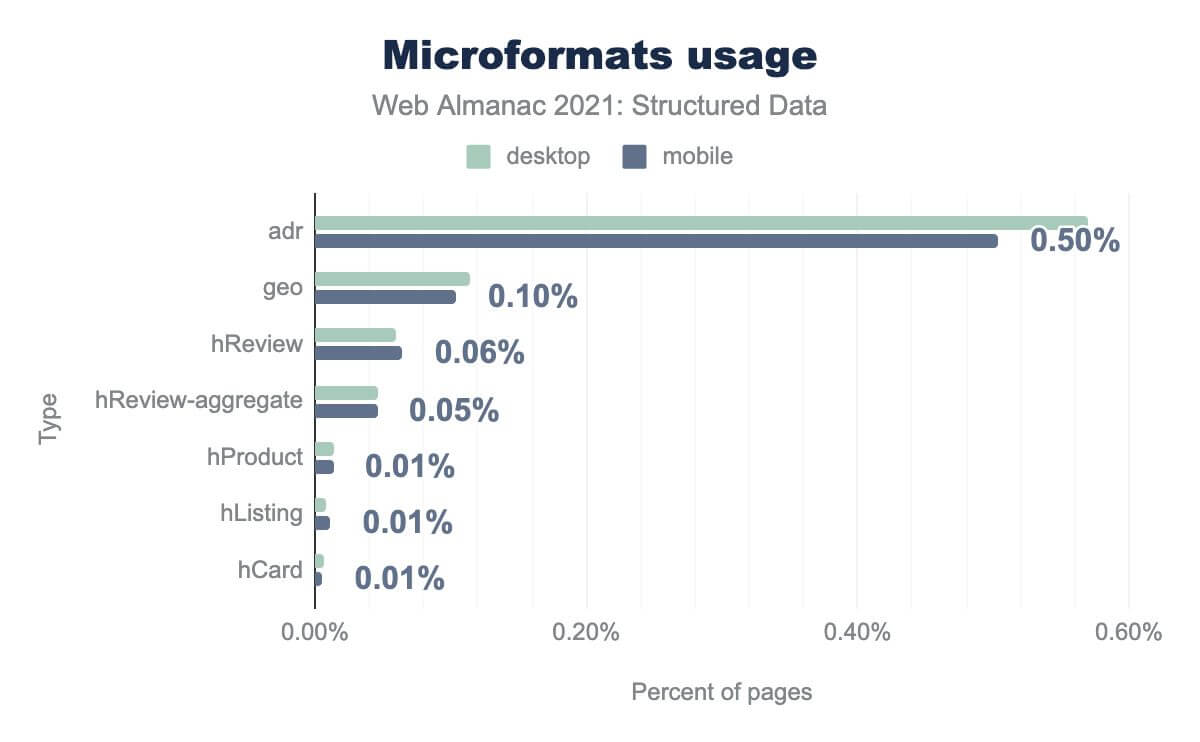
adr is on 0.50%, geo is on 0.10% hReview is on 0.06% hReview-aggregate is on 0.05% hProduct is on 0.01% hListing is on 0.01%, and hCard 0.01%. Desktop usage is similar.Historically and due to its nature (as an extension of HTML), Microformats have been heavily used by website developers to describe properties of businesses and organizations; particularly in pages promoting local businesses. This goes a long way to explaining the prominence of the adr property (on 0.50% of pages), reviews (hReview, on 0.06% of pages) and other information meant to characterize local businesses and their products/services.
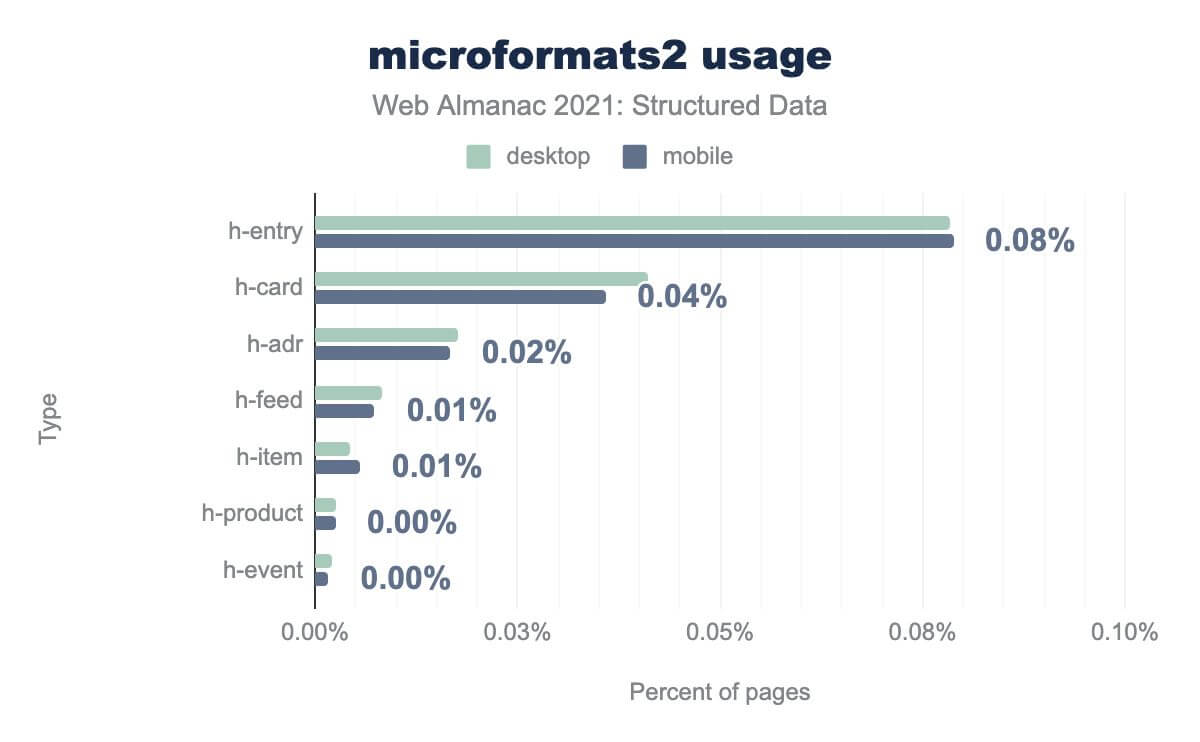
h-entry is on 0.08% h-card is on 0.04% h-adr is on 0.02% h-feed is on 0.01% h-item is on 0.01% h-product is on less than 0.01%, and h-event is on less than 0.01%. Desktop usage is similar.The difference between legacy microformats and the more modern version is significant, and an interesting insight into changing behaviors and preferences in the use of markup.
Where the adr class dominated the classic microformats data set, the equivalent h-adr property only occurs on 0.02% of pages. The results here are dominated instead by the h-entry property (on 0.08% of pages and which describes blog posts and similar content units), and the h-card property (on 0.04% of pages and which describes a business card of an organization or individual).
We can speculate on three likely causes for this difference:
- Data for common class names (like
adr) is almost certainly over-inflated in our microformats v1 data; where it’s difficult to distinguish between when these values are used for structured data vs more generic reasons (e.g., as an HTML class attribute value with associated CSS rules). - The use of microformats in general (regardless of type) has decreased significantly, and been replaced with other formats.
- Many websites and themes still include
h-entry(and sometimesh-card) markup on common design elements and layouts. For example, many WordPress themes continue to output ah-entryclass on the main content container.
Microdata
Like microformats and RDFa, microdata is based on adding attributes to HTML elements. Unlike microformats, but in common with RDFa, it’s not tied to a set of defined meanings. The standard is extensible and allows authors to declare which vocabularies of data they’re describing; most commonly schema.org.
One of the limitations of microdata is that it can be difficult to describe abstract or complex relationships between entities, when those relationships aren’t explicitly reflected in the HTML structure of the page.
For example, it may be hard to describe the opening hours of an organization if that information isn’t concurrent or logically structured in the document. Note that, there are standards and methodologies for solving this problem (e.g., by including inline <meta> tags and properties), but these aren’t widely adopted.
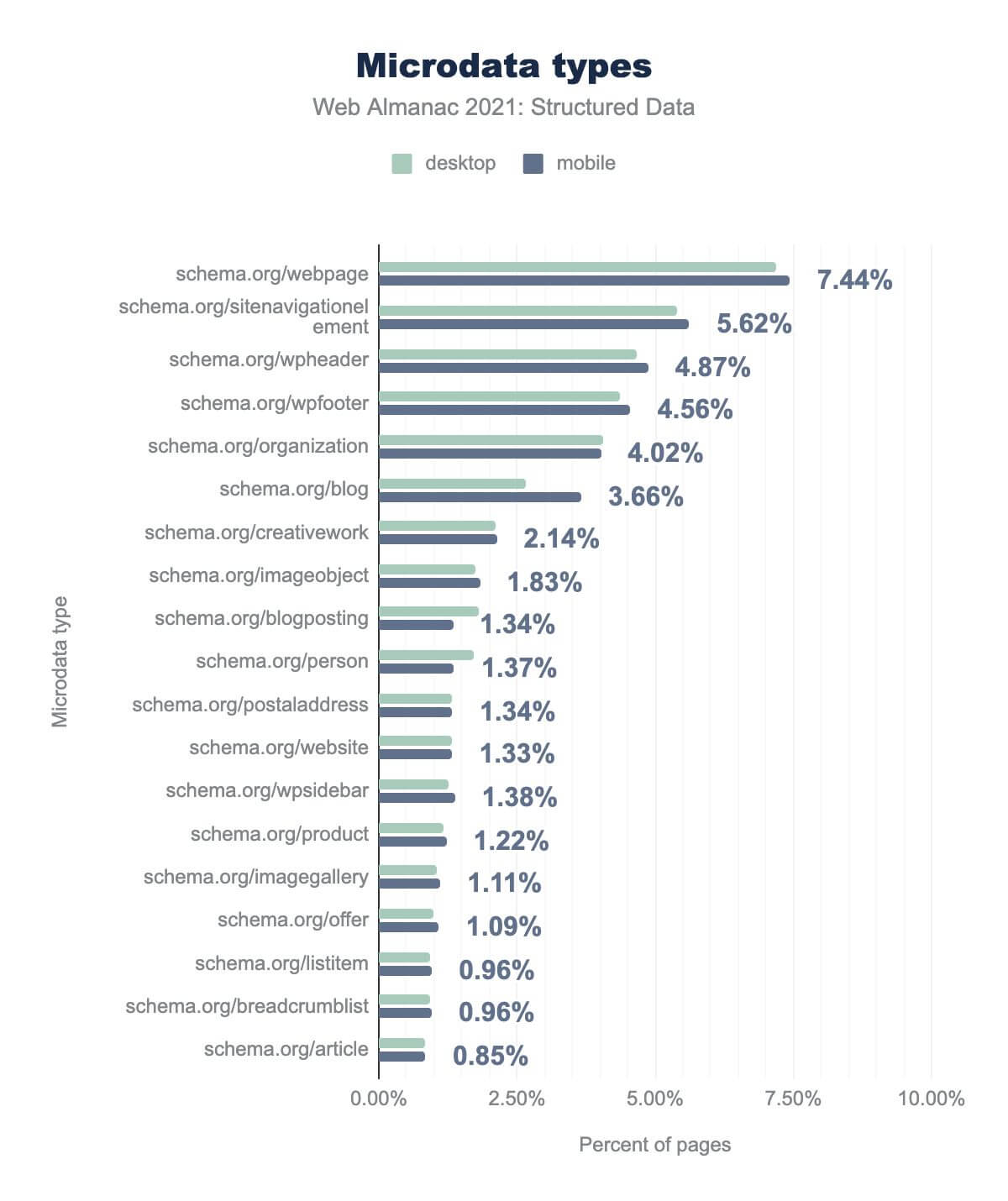
schema.org/ prefix): webpage is on 7.44%, sitenavigationelement is on 5.62%, wpheader is on 4.87%, wpfooter is on 4.56%, organization is on 4.02%, blog is on 3.66%, creativework is on 2.14%, imageobject is on 1.83%, blogposting is on 1.34%, person is on 1.37%, postaladdress is on 1.34%, website is on 1.33%, wpsidebar is on 1.38%, product is on 1.22%, imagegallery is on 1.11%, offer is on 1.09%, listitem is on 0.96%, breadcrumblist is on 0.96%, and article is on 0.85%. Desktop usage is similar.The most common types of microdata across the pages we analyzed describe the web page itself; via properties like webpage (7.44% of pages), sitenavigationelement (5.62% of pages), wpheader (4.87% of pages) and wpfooter (4.56% of pages).
It’s easy to speculate on why these types of structural descriptors are more prominent than content descriptors (such as person or product); creating and maintaining microdata requires content producers to add specific code to their content—and that’s often easier to do at template level than it is at content level.
Whilst one of the strengths of microdata is its explicit relationship with (and authoring in) the HTML markup, this has limited its approach to content authors with the technical knowledge and capabilities to use it.
That said, we see a broad adoption and variety of microdata types. Of note:
Organization(4.02%), which typically describes the company which publishes the website, the manufacturer of a product, the employer of an author, or similar.CreativeWork(2.14%) the most generic parent type to describe all written and visual content (e.g., blog posts, images, video, music, art).BlogPosting(1.34%), which describes an individual blog post (which commonly also identifies aPersonas an author).Person(1.37%) which is often used to describe content authors and people related to the page (e.g., the publisher of the website, the owner of the publishing organization, the individual selling a product, etc.).Product(1.22%) andOffer(1.09%), which, when used together, describe a product which is available for purchase (typically with additional properties which describe pricing, reviews and availability).
JSON-LD
Unlike microdata and microformats, JSON-LD isn’t implemented by adding properties or classes to HTML markup. Instead, machine-readable code is added to the page as one or more standalone blobs of JavaScript Object Notation. This code contains descriptions of the entities on the page, and their relationships.
Because the implementation isn’t tied directly to the HTML structure of the page, it can be much easier to describe complex or abstract relationships, as well as representing information which isn’t readily available in the human-readable content of the page.
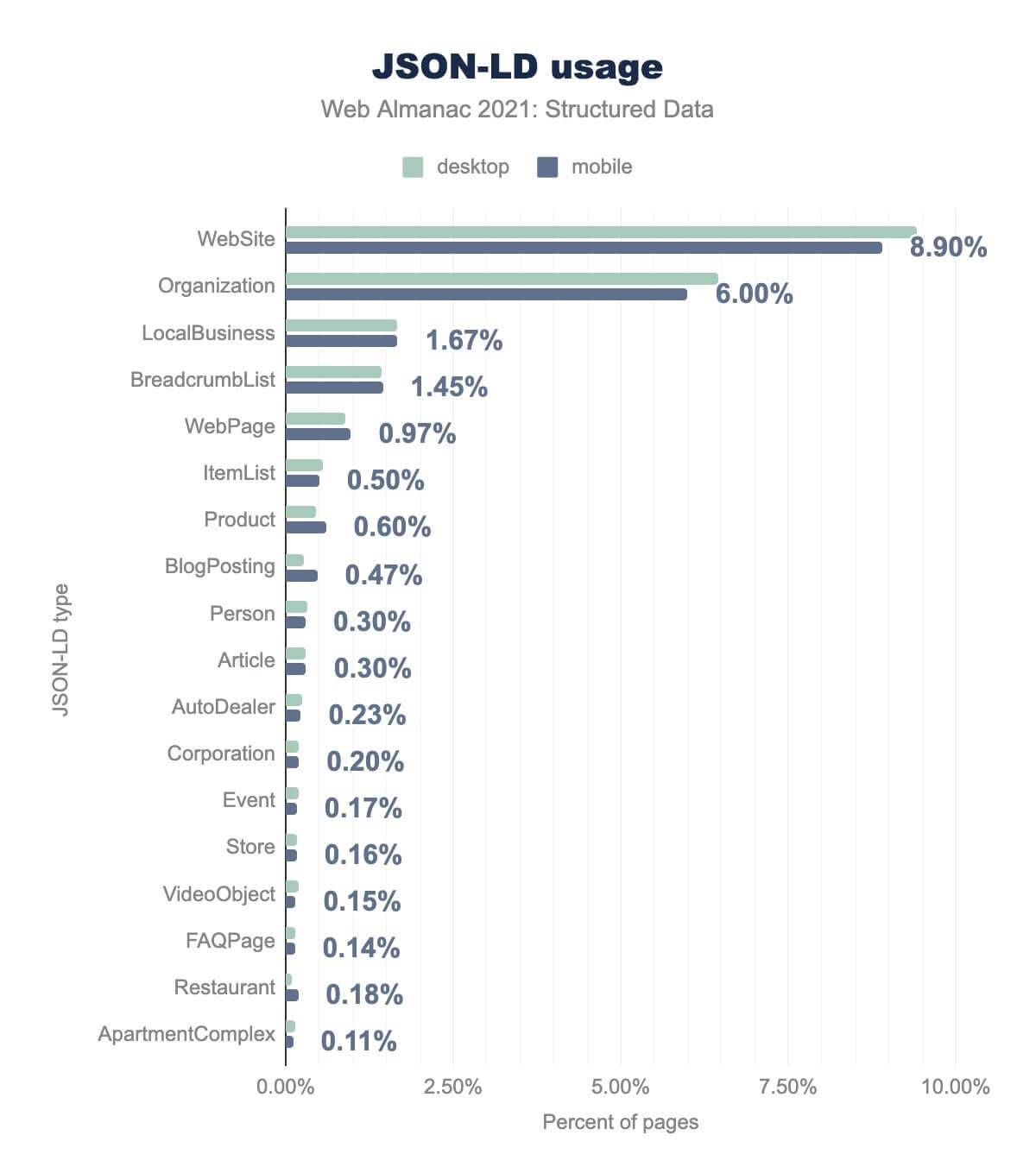
Website is on 8.90%, Organization is on 6.00%, LocalBusiness is on 1.67%, BreadcrumbList is on 1.45%, WebPage is on 0.97%, ItemList is on 0.50%, Product is on 0.60%, BlogPosting is on 0.46%, Person is on 0.30%, Article is on 0.30%, AutoDealer is on 0.23%, Corporation is on 0.20%, Event is on 0.17%, Store is on 0.16%, VideoObject is on 0.15%, FAQPage is on 0.14%, Restaurant is on 0.18%, and ApartmentComplex is on 0.11%. Desktop usage is similar.As we might expect, our findings are similar to our findings from evaluating the use of microdata. That’s to be expanded, as both approaches are heavily skewed towards the use of schema.org as a predominant standard. However, there are some interesting differences.
Because the JSON-LD format allows for site owners to describe their content independently of the HTML markup, it can be easier to represent more abstract complex relationships, which aren’t tied so strictly to the content of the page.
We can see this reflected in our findings, where more specific and structured descriptors are more common than with microdata. For example:
BreadcrumbList(1.45% of pages) describes the hierarchical position of the web page on the website (and describes each parent page).ItemList(0.5% of pages), which describes a set of entities, such as steps in a recipe, or products in a category.
Outside of these examples, we continue to see a similar pattern as we did with microdata (though at a much lower scale). Descriptions of websites, local businesses, organizations and the structure of web pages account for the majority of broad adoption.
JSON-LD structures & relationships
One key advantage of JSON-LD is that we can more easily describe the relationships between entities than we can in other formats.
An event, for example, may have an organizing corporation, be located at a specific location, and have tickets available on sale as part of an offer. A blog post describing that event might have an author, and so on, and so on. Describing these kinds of relationships is much easier with JSON-LD than with other syntaxes and can help us tell rich stories about entities.
However, these relationships can often become deep, complex and intertwined. So, for the purposes of this analysis, we’re only looking at the most common types of relationships between entities; not evaluating entire trees and relationship structures.
Below are the most common connections between types, based on how frequently they occur within all structure/relationship values. Note that some of these structures and values may sometimes overlap, as they’re small parts of larger relationship chains.
| Relationship | % of desktop pages | % of mobile pages |
|---|---|---|
WebSite > potentialAction > SearchAction |
6.44% | 6.15% |
| 5.06% | 4.85% | |
@graph > WebSite |
4.89% | 4.69% |
WebPage > isPartOf > WebSite |
4.02% | 3.81% |
@graph > WebPage |
4.01% | 3.79% |
BreadcrumbList > itemListElement > ListItem |
3.93% | 3.78% |
Organization > logo > ImageObject |
2.85% | 3.03% |
@graph > BreadcrumbList |
3.18% | 2.99% |
WebPage > potentialAction > ReadAction |
2.92% | 2.71% |
WebPage > breadcrumb > BreadcrumbList |
2.60% | 2.44% |
WebSite |
2.49% | 2.30% |
@graph > Organization |
2.26% | 2.13% |
WebSite > publisher > Organization |
2.22% | 2.09% |
Product > offers > Offer |
1.47% | 1.89% |
Product |
1.41% | 1.73% |
@graph > ImageObject |
1.80% | 1.71% |
ItemList > itemListElement > ListItem |
1.71% | 1.69% |
@graph > SiteNavigationElement |
1.70% | 1.66% |
WebPage > primaryImageOfPage > ImageObject |
1.67% | 1.59% |
The most common structure is the relationship between website, potentialAction, and SearchAction schema (accounting for 6.15% of structures). Collectively, this relationship enables the use of a Sitelinks Search Box in Google’s search results.
Perhaps most interestingly, the next most popular structure (4.85% of relationships) defines no relationships. These pages output only the simplest types of structured data, defining individual, isolated entities and their properties.
The next most popular structure (4.69% of relationships) introduces the @graph property (in conjunction with describing a website). The @graph property doesn’t is not an entity in its own right but can be used in JSON-LD to contain and group relationships between entities.
As we explore further relationships, we can see various descriptions of content and organizational relationships, such as WebPage > isPartOf > WebSite (3.81% of relationships), Organization > logo > ImageObject (3.03% of relationships), and WebSite > publisher > Organization (2.09% of relationships).
We can also see lots of structures related to breadcrumb navigation, such as:
BreadcrumbList > itemListElement > ListItem(3.78% of relationships)@graph > BreadcrumbList(2.99% of relationships)ItemList > itemListElement > ListItem(1.69% of relationships)
Beyond these most popular structures, we see an extremely long-tail of relationships, describing all manner of entities, content types and concepts; as niche as ApartmentComplex > amenityFeature > LocationFeatureSpecification (0.1% of relationships) and AutoDealer > department > AutoRepair (0.04% of relationships) and MusicEvent > performer > PerformingGroup (0.01% of relationships).
We should reiterate that these types of structures and relationships are likely to be much more common than our data set represents, as we’re limited to analyzing the home pages of websites. That means that, for example, a website which lists many thousands of individual apartment complexes, but does so on inner pages, wouldn’t be reflected in this data.

WebPage is the largest “From” item branching off to multiple “Relationship” types and “To” results (for example WebPage -> PotentialAction -> SearchAction). This is followed by WebSite, then Organization, Product, BreadCrumblist, BlogPosting and then a decreasingly used list of other items. Of the middle “Relationships” column PotentialAction is used most, followed by ItemListElement, IsPartOf, Publisher, image and then a similar long tail of ever-decreasing usage. The “To” column has ImageObject as the most used at the top, following by Organization, SearchAction, ListItem, WebSite, WebPage and then again a longer tail of every decreasing usage. The general sense created by the graph is a lot of different relationships with much cross-usage between the three columns.The diagram shows the correlation between JSON-LD entities on mobile pages and represent them as flows, visually linking entities and relationships. Each class represents a unique value in the cluster and the height is proportional to its frequency.
We’re limiting in the chart the analysis to the top 200 most frequent chains.
From the chart we also get first overview of the sectors behind these graphs from general publishing to e-commerce from local business to events, automotive, music and so on.
Relationship depth
Out of curiosity, we also calculated the deepest, most complex relationships between entities—in both our mobile and desktop data sets.
Deeper relationships tend to equate to richer, more comprehensive descriptions of entities (and the other entities they’re related to).
The deepest relationships are:
- On desktop, a depth of 18 nested connections.
- On mobile, a depth of 12 nested connections.
It’s worth considering that these levels of depth may hint at programmatic generation of output, rather than hand-crafted markup, as these structures become challenging to describe and maintain at scale.
Use of sameAs
One of the most powerful use-cases for structured data to declare when an entity is the sameAs another entity. Building a comprehensive understanding of a thing often requires consuming information which exists in multiple locations and formats. Having a way in which each of those instances can cross-reference the others makes it much easier to “connect the dots” and to build a richer understanding of that entity.
Because this is such a powerful tool, we’ve taken the time to explore some of the most common types of sameAs usage and relationships.
sameAs declarations on pages across the web. Of all mobile in our data: facebook.com occurs on 4.26%, instagram.com occurs on 2.74%, twitter.com occurs on 2.46%, youtube.com occurs on 1.78%, linkedin.com occurs on 1.04%, pinterest.com occurs on 0.60%, google.com occurs on 0.51%, yelp.com, wikidata.org occurs on 0.12%, wikipedia.org occurs on 0.11%, tumblr.com occurs on 0.08%, uptodown.io occurs on 0.10%, vk.com occurs on 0.08%, soundcloud.com occurs on 0.04%, vimeo.com occurs on 0.03%, pinterest.co.uk occurs on 0.03%, tripadvisor.com occurs on 0.03%, t.me occurs on 0.03%, and flickr.com occurs on 0.02%. Desktop usage is similar.The sameAs property accounts for 1.60% of all JSON-LD markup and is present on 13.03% of pages.
We can see that the most common values of the sameAs property (normalizing from URLs to hostnames) are social media platforms (e.g., facebook.com, instagram.com), and official sources (e.g., wikipedia.org, yelp.com)—with the sum of the former accounting for ~75% of usage.
It’s clear that this property is primarily used to identify the social media accounts of websites and businesses; likely motivated by Google’s historical reliance on this data as an input for managing knowledge panels in their search results. Given that this requirement was deprecated in 2019, we might expect this data set to gradually alter in coming years.
Conclusion
Structured data is used broadly, and diversely, across the web. Whilst some of this is undoubtedly stale (legacy sites/pages, using outmoded formats), there is also strong adoption of new and emerging standards.
Anecdotally, much of the adoption we see of modern standards like schema.org (particularly via JSON-LD) appears to be motivated by organizations and individuals who wish to take advantage of search engines’ support (and rewards) for providing data about their pages and content. But outside of this, there’s a rich landscape of people who use structured data to enrich their pages for other reasons. They describe their websites and content so that they can integrate with other systems, so that they can better understand content, or in order to facilitate others to tell their own stories and build their own products.
A web made of deeply connected, structured data which powers a more integrated world has long been a science-fiction dream. But perhaps, not for much longer. As these standards continue to evolve, and their adoption continues to grow, we pave a road towards an exciting future.
Future years
In future years we hope to be able to continue the analysis started here, and to map the evolution of structured data usage over time.
We look forward to exploring further.

